
ETHICAI, winning team of the the AI4Good Academic Award, aims to investigate the biases found in common natural language processing tools, and present findings in an accessible way.
Follow ETHICAI through their journey, generously supported by Concertation Montreal, and find out where they're headed next!
Keywords: AI, ethics, NLP, word embeddings, research
INTRODUCTION
During the AI4Good Lab, our team loved exploring how Artificial Intelligence (AI) could be used to do good in the world. Listening to talks from amazing researchers during the Lab inspired our team to think about the concept of “AI for Good” from a different angle: how can we evaluate the AI tools and systems already in use today? How can we make sure that our systems are not discriminating, are free of bias, and are behaving ethically?

AI systems are increasingly pervasive in our world, and can have a serious impact on our
everyday lives. They make decisions about what content we see, what opportunities we receive, how others perceive us, and more. AI is being deployed in fields as innocuous as finding movies for you to watch, and as critical as diagnosing health care conditions or determining whether you can receive a loan. Part of this is due to an explosion of easy-to-use, open source tools that make creating AI systems easier than ever. This has played a huge role in democratizing AI, and these tools form the foundation of hundreds of AI systems today. However, if these tools contained serious biases, then that bias could silently propagate into the AI systems that use them.

Thus, for our project, we decided to focus on AI ethics and bias in existing open-source tools. We had two general goals during our time in the lab:
- To take a wide look at the field of AI ethics, to review issues that have been found in the past and look at ways researchers are uncovering and solving ethical problems.
- To then select an open-source tool and conduct a brief analysis to try and uncover possible sources of bias in it.
BEGINNING OUR PROJECT
When we started the project, our first step was picking a domain to study, a bias to examine, and a tool to test. What did we want to study? Which tool did we want to focus on? What’s driving our motivation to study this topic? We poured over research articles and news stories, sifting through topics like Computer Vision, Natural Language Processing (NLP), Recommender Systems, Sentiment Analysis and Affect Recognition, and systems which automate decisions on applications. Within those domains, we looked at common datasets, models and tools to find candidates to analyze.
We also considered biases we were interested in examining. Gender bias and race/ethnic/cultural bias have gotten some attention in recent years, especially with high-profile research such as Gender Shades. We studied these, as well as some more overlooked types of bias such as socioeconomic status, biodata (age, health condition, and others), and ability.
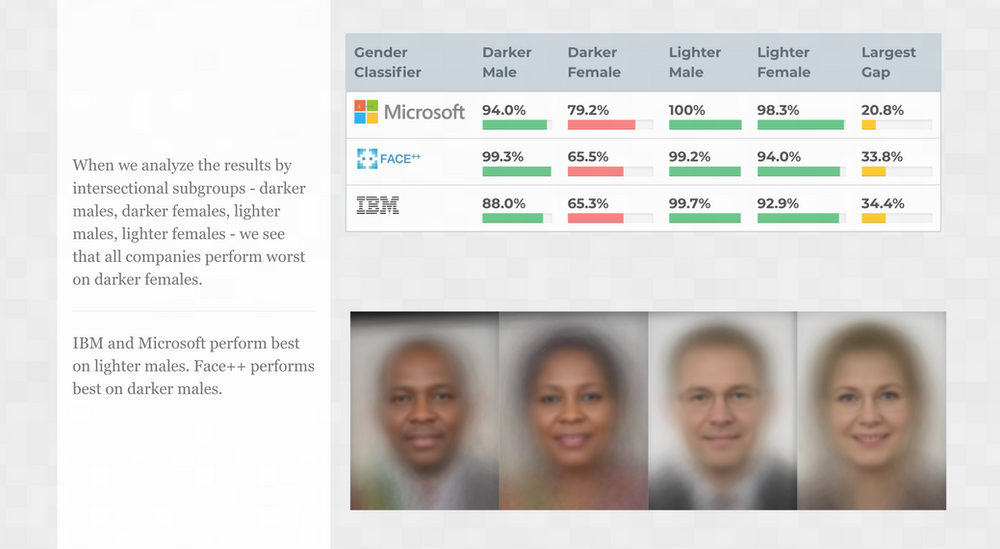
Figure 2: Image of some results found by the researchers of Gender Shades: classifiers built to identify gender from an image performed worse on darker faces than lighter ones
After discussing our preferences and evaluating the wealth of research available, we chose to focus on NLP tools for our project. In particular, we were inspired by papers such as “Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings,” which scrutinized gender bias in word embeddings trained on the Google News corpus, word2vec. We considered other publicly available tools for creating and using word embeddings, and eventually settled on analyzing Facebook’s fastText. In terms of a less-examined bias, we decided to narrow our focus to ageism; in particular, dialogue surrounding the COVID-19 pandemic and subsequent “reopening” in the summer of this year led to a lot of conversations comparing the health and lifestyles (and sometimes even the “worth”) of young vs. old people.
A BIT ABOUT WORD EMBEDDINGS
Word embeddings are a vector-based representation of words, which can be used in language models. Every word is represented as a sequence of N real numbers, which embeds it at some particular point in N-dimensional space. Using word embeddings, rather than raw words, is useful in NLP because they make words comparable. By creating this N-dimensional space, we can find the distance between words: the idea is that words which represent similar concepts should be close together in space, and words which are dissimilar should be farther away., This also allows us to find connections and analogies between words: the direction and distance between similar word pairs should be similar, such as the difference between “France - Paris” and “Italy - Rome”.
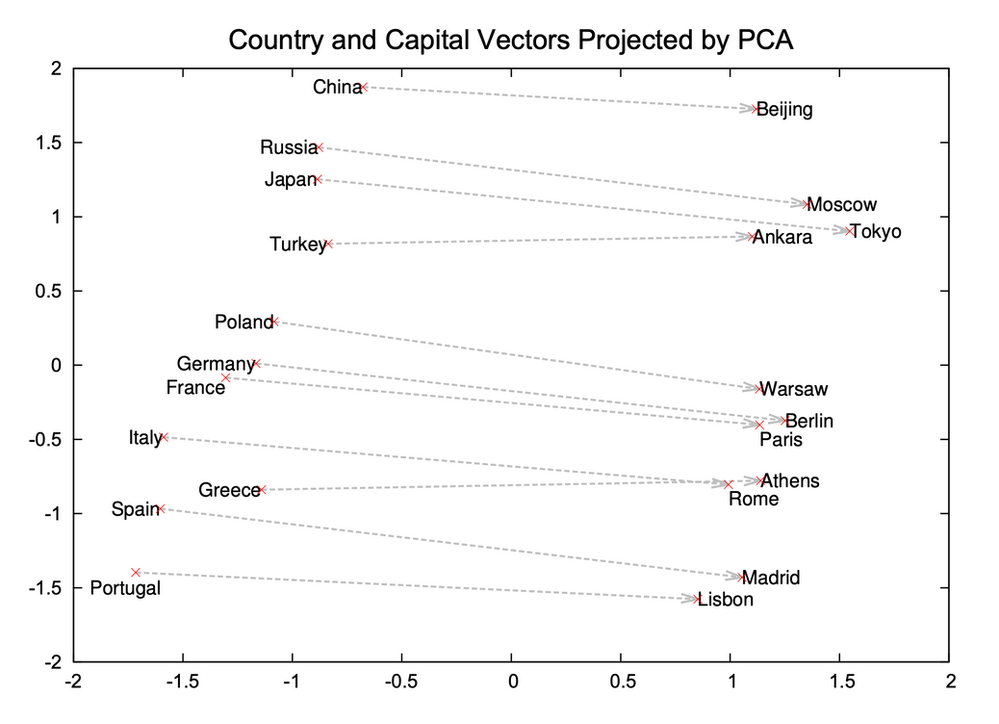
Figure 3: A plot from Mikolov et al.’s Distributed Representations of Words and Phrases and their Compositionality showing how the projected vectors between countries and their capitals in word2vec have comparable length and direction
fastText is a tool created by Facebook’s AI Research (FAIR) lab that is an extension of the word2vec model. It is used for text classification and learning word embeddings using morphological word representations. One advantage of fastText is that it has the ability to compute word representations for words that don’t appear in the training data. fastText comes with several sets of pre-trained word vectors on different corpuses, including dumps of text from Wikipedia or Common Crawl, and is available in 157 languages, though we focused only on English in our project.
OUR FINDINGS AND CHALLENGES
With the help of our mentors, our next step was to define our research question. After our very first conversation with our professional mentor, Spandana Gella, we quickly appreciated how valuable and informative it is to have a mentor with experience using fastText. Using her advice, we were able to refine our project goals. Our project focused on two components for evaluating biases: visualization and model comparison.
For the visualization component, we wanted to visualize the relationships between words in fastText’s pre-trained word embeddings by projecting them onto a particular cultural axis (such as the direction between “she - he” or “young - old”). This would allow us to see where words which should be neutral with respect to a given axis may have been infused with bias from the dataset. For example, a word like “mother” should fall closer towards the word “she” versus “he” along this axis, but a word like “emotional” should not.

Figure 4: A projection of several competency-related words onto the old-young axis in fastText’s pretrained embeddings. Note that this plot has been split in order to fit inline, with the “old” side above and the “young” side below
Above is an example of projections we created from the fastText word embeddings. Some words like “ancient” and “decrepit” are, as expected, more strongly associated with old than young, but we also see negative competency-related words on the old side, like “inefficient” and “useless.” On the flip side, youth is associated with being “inexperienced,” but also “savvy” and “competent.”
For the model comparison component, we wanted to assess the underlying bias in the pre-trained word embeddings by using them to create a classification model on a bias-related task. In this case, we chose a dataset related to the sentiment of age-related statements. Our hypothesis was that if the word embeddings contained ageism, then the model would be more likely to classify statements about older people more negatively than young people compared to the labelled data. We used fastText’s built-in tools for creating classification models to create neural networks using varying parameters, and evaluated their performance against the dataset.
Unfortunately, our results were inconclusive about whether ageism affected the classification accuracy of this model. None of the models performed much better than a naive, random guess. One possible explanation is that this ageism dataset itself is not suited for this classification task: it contains statements pulled from social media and scored by researchers, which contain a variety of writing styles, slang, misspellings, and other problems common when dealing with raw text. A better solution for the future might be to come up with a small, hand-crafted set of sentences specifically designed to detect ageism.
For continued work on this project, we hope to explore more types of biases and to work towards creating a web tool to allow users to easily create their own visualizations from word embeddings to help explore their own problems with bias!
LESSONS LEARNED FROM THE LAB
Several guest speakers in the AI4Good Lab really changed our perspective on the AI research landscape. Joelle Pineau from Mila and McGill University gave a talk on reproducibility that opened our eyes to the challenge of how difficult it can be to verify results. The scientific community has had an exponential growth in the number of papers discussing various technologies of AI and Machine Learning. There needs to be better oversight and review of the papers being produced, and better understanding of how to interpret and apply the results of experiments.
Layla El Asri from Borealis AI spoke about the challenges of NLP, both in terms of securing data which is free of bias and ethically sourced, and in terms of verifying that models are behaving the way you expect them to. Many biases in AI applications stem from the corpus of data they’re trained on; if the corpus of data is biased to begin with, models trained on it will further exacerbate the problem, while obscuring the source of the bias. We must address our own biases first, and do our best to ensure they don’t enter the data we use to train powerful AI models.
As a society we use AI to give us the answers to a lot of our questions. We have to make sure we ask the right questions. We need to consider the ethical implications of this technology as it becomes woven into our public and private lives. In her talk, Negar Rostamzade of Google pointed out that in today’s AI ecosystem, we often don’t consider the implications of an AI system before building it. We should be asking “Is this even necessary?” before we begin development! Consequently, we see headlines after a technology has been brought to market which highlights how it negatively impacts stakeholders in society. These headlines showcase how imperfect AI systems really can be, and remind us that we should not trust technology without question, no matter how confidently it produces an answer.
We’re proud that we worked on a project to create awareness of how existing societal biases can be amplified by technology. We want to develop technology to improve our lives and society. Because of this, we need to do our best to exterminate biases against marginalized groups every step of the way. As such, we cannot leave AI unchecked. As creators of technology, we are ultimately accountable and responsible for its impact. Going forward, having completed the AI4Good Lab, we want to ensure that the technology we produce will have a positive impact on the world.
ACKNOWLEDGEMENTS
There are many individuals we would like to thank for helping make our project a reality. To Aga Slowik, thank you for being our Teaching Assistant and for keeping us on track. To our incredible mentor, Spandana Gella, thank you for being instrumental in narrowing our research scope and guiding us through the project. To Ryan Lowe, thank you for consulting with us about AI ethics. To Anita Gergely and Maude Lizaire, thank you for all of your advice about careers in AI and for your encouragement throughout the project. We also want to thank the phenomenal team behind the AI4Good Lab for making this opportunity a reality!